Spring Cloud Config
스프링 클라우드 컨피그는 분산 시스템 환경에서(ex. MSA 방식이 적용된 애플리케이션)
중앙 집중식 구성관리를 제공하는 프레임워크다. 각 애플리케이션의(ex. 주문 서비스, 배달 서비스...)
└ 모든 마이크로서비스의 설정을(각 서비스의 야믈파일에 작성한 설정값을) 중앙에서(Spring Cloud Config) 관리한다.
설정을(*.yml) 중앙에서 관리하고, 변경사항을 실시간으로 반영할 수 있다.
Git, 파일 시스템, JDBC 등 다양한 저장소에서 중앙에서 관리하는 설정파일을 저장하고, 수정하고 관리할 수 있다.
Config 서버 구성
1. 각 서비스의 설정들을 해당 어플리케이션에서 관리하려면 의존성이 필요하고,
build.gradle 에 Spring Cloud Config 기능을 사용하기 위한 의존성을 추가한다.
// build.gradle
dependencies {
implementation 'org.springframework.cloud:spring-cloud-config.server'
implementation 'org.springframework.boot:spring-boot-starter-web'
}

Spring Cloud Config 서버의 설정 값을 클라이언트(분산된 각 서비스) 에서 참조해서 사용하려면
└ Config 클라이언트
Config 클라이언트(각 서비스) 에서는
1. build.gradle 에 'org.springframework.cloud:spring-cloud-starter-config' 의존성을 추가한다.
그리고 2. 설정파일에(application.yml) config 서버의 설정을 작성한다.
# (여기는 클라이언트의 application.yml 파일) Config 클라이언트의 name 을 정의
# eureka 서버에게 해당 서비스의 이름과 위치를 등록하는 것
# (자동 등록됨 단, build.gradle 에 의존성 추가해야함)
spring:
application:
name: my-config-client
# spring cloud 서버에서 이 서비스의 설정을 관리하고 있는데(중앙집중식 관리)
# 그 설정 값을 받아오기 위해 spring cloud config 서버의 서비스 아이디를 작성해준다.
# 그래야 eureka 서버가 spring cloud config 서버의 서비스를 찾아서
# 해당 어플리케이션의 설정 정보를 갖고와서 사용할 수 있는듯?
cloud:
config:
discovery:
enabled: true
service-id: config-server # spring-cloud-config-server의 id
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka # 유레카의(서비스 디스커버리) 주소
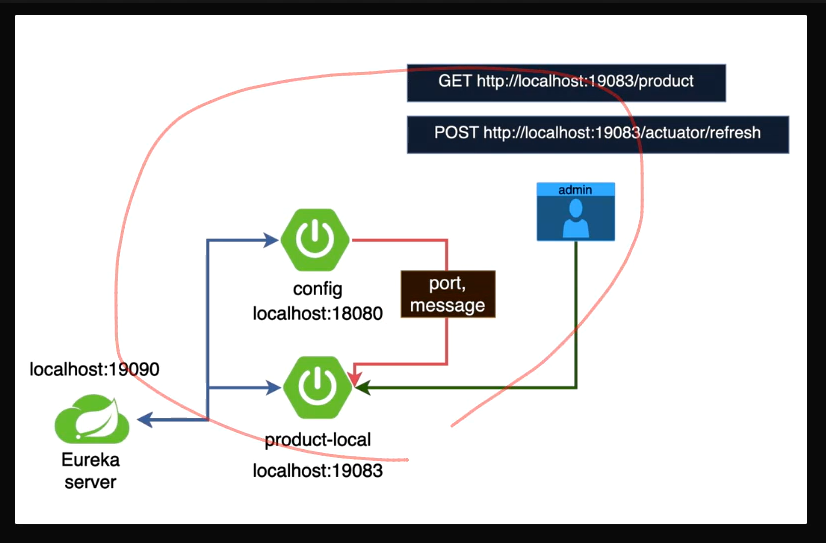
Spring Cloud Config 서버의 설정 값을 클라이언트(분산된 각 서비스)가 가져오는 과정
1. spring cloud config server 를 eureka 서버에 등록하고
: eureka 서버를 기준으로 spring cloud config server는 eureka client 가 됨.
: eureka 서버는 eureka 클라이언트의 위치와 서비스명(애플리케이션 이름) 값을 갖고 있음
2. 분산된 서비스에서 spring cloud config server 에 설정되어 있는 해당 서비스의 설정을 갖고와서 사용할 것임
spring cloud config server 에서 (Config Server 에 설정되어 있을 값을 가져와서 사용하려는)
서비스의 port 와 message 를 가져 온다.
분산추적(Spring Cloud Sleuth) 및 로깅(zipkin)
분산 추적이란 분산 시스템에서 서비스 간의 요청흐름을 추적하고 모니터링 하는 방법이다.
마이크로서비스 아키텍쳐에서(MSA) 여러 서비스가 협력하여 하나의 요청을 처리한다.
1. 서비스 간의 호출하면서 발생한 문제들의 원인 파악
2. 서비스 간의 명확한 호출 흐름 인지
3. 서비스 간의 호출 관계에서 발생한 성능 병목이나 오류를 빠르게 진단하기 위해
분산 추적이 필요하다.
MSA 방식에서
1. 클라이언트(브라우저)로부터 요청이 서비스로 들어옴: Client --- request → Order Service(주문 애플리케이션)
2. 서비스간 필요한 서비스 호출: Order Service --- 호출 → Product Service --- 호출 → User Service
각 서비스를 하나하나 호출하게 됨. 문제가 생긴다면 어디서 생겼는지 확인하기가 어렵게 되는데
분산 추적을 사용하면 어떤 서비스에서 문제가 발생했는지 확인할 수 있고, 해당 서비스에 한해서 오류를 테스트할 수 있게된다.
ZipKin 서버 실행은 도커를 사용하여 실행할 수 있다 → 집킨 사용 일시 보류
이벤트 드리븐 아키텍쳐는 시스템에서 발생하는 이벤트를 기반으로 동작하는 소프트웨어 설계 스타일이다.
┗ 이벤트는 비동기적으로 처리되며, 서비스 간의 느슨한 결합을 통해 독립적으로 동작할 수 있게 한다.

'[부트캠프] kdt 심화 과정' 카테고리의 다른 글
| 4계층, JPA와 리플렉션, JPA auditing 기술 (1) | 2025.04.21 |
|---|---|
| 2025년 4월 7일 (0) | 2025.04.07 |
| MSA(Microservices Architecture) 서킷브레이커 (0) | 2025.03.12 |
| MSA(Microservices Architecture) 서비스 디스커버리, 로드 밸런싱 (0) | 2025.03.11 |
| 2025년 3월 10일(월) (1) | 2025.03.10 |