관계형 모델 ( Relation Model, 논리적 모델링에서 가장 많이 사용된다 )
데이터베이스 분야에서 테이블 ( Table ) 은 릴레이션 ( Relation ) 이라고 한다.
속성들과 관계를 갖고 맺어진 ( 하나의 ) 레코드 ( row ) 들이 모여 하나의 릴레이션을 이룬다.
릴레이션과 릴레이션으로 이루어진 데이터들의 구조를
Relational Data Model ( 관계형 데이터 모델, 관계형 DB, RDB ) 이라고 한다.
데이터베이스 분야에서
테이블 ( Table )은 릴레이션 ( Relation ) 으로
→ 릴레이션은 record 와 field 의 2차원 구조로 데이터가 저장된 객체다.
컬럼 ( Column ) 은 필드 ( Field ) 나 어트리뷰트 ( Attribute ) 로
→ 릴레이션에서 세로 방향으로 이루어진 각 속성을 말한다.
행 ( Row ) 은 레코드 ( Record ) 나 튜플 ( Tuple ) 이라는 용어를 사용한다.
→ 릴레이션에서 가로 방향으로 이루어진 연결된 데이터를 말한다.
Relation Model Constraints
1. 도메인 제약 ( Domain Constraints )
속성 ( = 컬럼 = 필드 ) 에 매핑된 속성 값은 원자성을 가지며,
( 속성 값은 ) 도메인에서 정의된 값이어야 한다.
도메인에서 정의된 값이 아니라면 도메인 제약에 위배되었다고 한다.
→ 도메인 제약은 속성에 대한 제약으로 속성을 작성할 때,
부가적으로 설정되는 데이터, 메타데이터에 정의하는 데이터에 속할 것 같다.
예를 들어 '나이' 라는 필드에 매핑되는 값의 타입은 숫자여야 하고,
1 이상이면서 200을 초과할 수 없다 등의 조건을 설정할 수 있고,
이 조건에 포함되는 값이 아니라면 도메인 제약에 위배된 것이다.
값이 매핑되어 있지 않다고 해서 ( → 값이 비어있는 경우 )
도메인 제약에 위배된 것은 아니다. 단, Not Null이 아닌경우에
속성 값이 원자성을 가진다는 것은
( 속성 값이 ) 더 이상 쪼개질 수 없는 데이터여야 한다는 것,
더 이상 쪼개질 수 없는 데이터는
쪼개질 수 있는 [ 분리 가능한 ] 데이터를 갖는 속성인 Composite Attribute 와
여러 개의 데이터를 갖는 속성인 Multivalued Attribute 는 허용되지 않는다는 것이다.
ER Model 에서의 Composite Attribute 와 Multivalued Attribute 를
RDB 로 바꿀 때 원자성을 가질 수 있게 바꾸어 주어야 한다.
2. 키 제약 조건 ( Key Constraint )
릴레이션에서 모든 각각의 튜플 ( Tuples ) 은 서로 식별 ( 구분 ) 가능해야 한다.
→ 테이블의 모든 레코드는 구분가능해야 한다.
각 튜플 ( = 레코드 = 행 )을 구분할 수 없다면 키 제약조건에 위배되는 것이다.
어떤 속성에 매핑되는 값들이 절대로 중복되지 않는 경우,
해당 속성 ( ex. 주민번호, 학번 등 ) 들을 키로 설정할 수 있고,
키로 설정할 수 있는 속성들을 후보 키 ( Candidate Key ) 라고 하고,
후보 키는 각 튜플을 식별할 수 있지만 2개의 키는 필요하지 않기 때문에
후보 키중 설계자가 대표로 지정한 속성을 Primary Key ( 주키, 기본키, PK ) 라 한다.
Super Key 는 ( 각 튜플을 ) 유일하게 식별해낼 수 있는 속성들의 집합인데,
최소성을 유지하기 위해서 빼도 되는 속성을 모두 빼면 후보 키,
후보 키중에 대표를 설정하면 기본 키가 된다.
3. 개체 무결성 제약
기본 키 ( PK - Primary Key )는 UNIQUE & NOT NULL 이어야 한다.
→ pk에 들어가는 값은 중복되어서는 안되고 ( UNIQUE )
비어 있어도 안된다 ( NOT NULL ) → ( PK is ) UNIQUE and NOT NULL.
4. 참조 무결성 제약 ( Referential Integrity Constraints )
외래키 ( FK - Foreign Key )
릴레이션간 관계를 맺고 있는데,
그 관계는 어떤 릴레이션이 다른 릴레이션을 참조할 때 맺어진다.
예를 들어 학생 릴레이션에서 소속이라는 필드가
학과 릴레이션의 학과명 필드를 참조한다면,
학생 릴레이션과 학과 릴레이션은 관계를 맺는 것이다.
학생 테이블 : 외래 키 → 소속
학과 테이블 : 기본 키 → 학과명
학생 테이블의 소속이라는 속성은 학과 테이블의 학과명을 참조하는 외래 키다.
외래 키는 자기 자신이 속한 릴레이션을 ( 셀프 ) 참조할 수도 있다.
FK는 UNIQUE 하지 않아도 된다 ( 중복되도 상관없다 )
FK는 Null 값이어도 상관 없다.
단, Null 이 아닌 경우 그 값이 참조하는 ( 릴레이션에서의 ) 필드에
실제로 존재하는 값으로 구성되어야 한다.
ER - to - Relational Model 변환 규칙
→ 개념적 모델링에 대한 결과를 관계적 모델링으로 바꾸는
[ ERD를 테이블간의 관계로 바꾸는 ]규칙들
1. Entity ( Strong Entity 와 Weak Entity ) 를 테이블로 바꾼다.
Strong Entity의 경우
ERD에서 직원이라는 Entity ( 개체 ) 가 있을 때

직원 개체에 있는 속성들에 기반하여 테이블 ( 릴레이션 ) 을 만든다 ↓
직원
| 이름 | 주민번호 | 생년월일 | 시도 | 상세주소 | 성별 | 급여 |
1 ) 직원 Entity 를 직원 테이블 ( 릴레이션 ) 로 만든다.
2 ) 직원 Entity 의 속성들 ( 이름, 주민번호, 성별, 생년월일, 급여, 주소, 시도, 상세주소 ) 을 테이블의 컬럼 ( 필드 ) 으로 설정한다.
단, Composite Attribute인 주소는 삭제하고, 분해된 속성만 컬럼에 작성해준다.
Multivalued Attribute는 따로 테이블을 만들어준다.
3 ) ER 다이어그램에서 identifier인 주민번호를 테이블에서 pk로 설정한다.
Weak Entity의 경우
Weak Entity를 테이블로 만들 때, Strong Entity와 같이 속성들을 컬럼으로 작성해준다.
단, 키를 만들기 위해서 건너편에 있는 Strong Entity의 identifier를 컬럼으로 가져온다.
Weak Entity로 만들어진 릴레이션에서
Strong Entity의 identifier와 partial key가 합쳐져 만들어진 값으로
각 튜플을 구분할 수 있게 된다.

부양가족
| 직원 주민번호 | 부양가족명 | 성별 | 생년월일 | 관계 |
1 ) 부양가족 Entity는 identifier가 없기 때문에 Weak Entity다.
ER Model 에서는 identifier 가 없어도 되지만,
Relational Model 에서는 identifier를 설정해야 한다.
( identifier를 설정하지 않으면 개체 무결성 제약에 위배된다 )
Relational Model 에서 ( 부양가족 Entity의 ) pk를 설정하기 위해
identifying relationship ( 부양 ) 의 건너편에 있는 직원 개체 ( Strong Entity ) 의
pk를 가져와 부양가족 테이블의 컬럼에 작성한다.
→ 부양가족 Entity의 기본 키는 직원 개체의 pk ( 부양가족 릴레이션에서 외래 키로 포함 시킴 )와
부양가족 Entity의 부분 키 ( partial key ) 조합으로 구성된다.
2. 1 : N ( or N : 1 ) 에 해당하는 2차 관계는 테이블을 만들 때 없앤다.
1 : N ( or N : 1 ) 관계는 테이블로 만들지 않고,
해당 관계를 1 의 반대편에 있는 테이블의 필드로 추가하고,
추가된 필드는 외래 키가 된다.

( 하나의 ) 부서는 여러 명의 직원이 소속될 수 있다.
( 한 명의 ) 직원은 최대 1개 부서에 소속될 수 있다.
직원 ( 개체 ) --------- N ----------- 소속 --------- 1 --------- 부서 ( 개체 )
이런 경우 직원 릴레이션에 소속 ( 관계 ) 를 필드로 추가하고,
추가된 필드 ( 소속 ) 는 외래 키가 되는데,
( 직원 개체의 ) 외래 키인 소속은 부서 개체의 pk인 부서번호에 대응되어야 한다.
3. M : N 또는 N-ary 관계는 테이블로 만든다.

직원 개체와 프로젝트 개체가 참여 관계를 이루는데 ( 2차 관계 )
이러한 ( 2차 ) 관계가 여러 개 있을 때 ( M : N 관계 )
직원 개체와 프로젝트 개체에 대응하는 참여 관계를 새로운 릴레이션으로 생성한다.
참여 관계를 릴레이션으로 생성했을 때,
참여 관계에 속한 모든 simple attributes 를 참여 릴레이션의 컬럼에 추가하고,
직원 릴레이션과 프로젝트 릴레이션의 기본 키를 참여 릴레이션의 컬럼에 외래 키로 추가설정한다.
참여 릴레이션의 기본 키는 직원 릴레이션에서 갖고 온 외래 키와
프로젝트 릴레이션에서 갖고 온 외래 키의 조합으로 구성된다.
참여
| 직원 주민번호 | 프로젝트 번호 | 주당 근무시간 |
참여 릴레이션의 기본 키는 직원 주민번호 필드와 프로젝트 번호 필드의 조합으로 구성된다.
합성이 되어서 키를 만들었기 때문에 Composite Key 라고 한다.
4. Multivalued attributes 는 테이블로 만든다.
어떤 개체의 속성 중 어떤 속성이 여러 개의 값을 갖는 경우
해당 속성은 테이블을 따로 만들어준다.
예를 들어 부서 개체의 속성이
부서명, 지역 ( Multivalued attributes ), 부서번호 (pk) 가 있는 경우,
Multivalued attributes 인 지역을 릴레이션으로 만든다.
만들어진 지역 릴레이션의 속성으로는 자기 자신 ( 지역 ) 과
자신 ( 지역 ) 이 속해 있었던 개체의 기본 키를 속성에 포함시킨다 → 지역 릴레이션의 외래 키
지역 릴레이션의 기본 키는 외래 키와 MA 속성의 조합으로 구성된다.
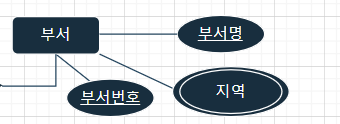
부서_지역 → 부서 개체의 Multivalued Attributes 인 지역을 릴레이션으로 생성했을 때
| 부서번호 | 부서지역 |
부서
| 부서명 | 부서번호 | 관리자 주민번호 | 관리시작일 |
일반화 개체 관계 다이어그램 ( Generalization ERD ) 을 릴레이션으로 만들 때

엔지니어 ISA 사람 → 엔지니어는 사람이다.
엔지니어 개체는 사람 개체의 속성을 모두 갖는다.
이런 경우 엔지니어 릴레이션을 만들 때 사람 릴레이션의 기본 키를
엔지니어 릴레이션의 키로 복제해준다.
ERD를 기반으로 릴레이션을 만들었을 때
복잡한 ( 데이터가 중복되는 ) 릴레이션 구조로 만들어질 수 있어
ERD를 Relational Model 로 바꾼 후에 한 번 더 검사하게 되는데
이 때 사용되는 도구가 정규화 ( Normalization ) 다.
→ 정규화 : 지저분한 릴레이션을 깨끗하게 만드는 과정
깨끗하게 만들어지는 정도에 따라
1차 / 2차 / 3차 정규화로 분류된다.
정규화의 핵심은 함수적 종속성 ( FD : Functional Dependency )
학번은 나이를, 성별을, 이름을 결정한다.
→ 학번의 값이 정해지면 그 값에 해당하는 나이, 성별, 이름의 값이 정해져 있다.
→ 학번은 성별을 결정하고 ( determine ) 성별은 학번에게 종속된다 ( dependency )
→ 학번과 성별 사이에 Functional Dependency 가 존재한다.
Functional Dependency 는 잘 짜여진 DB 라면
항상 pk 를 통해 다른 속성에 해당하는 값들을 알 수 있다.
참고 강의
1. 데이터베이스실무(SQLD대비) | 김남규 교수
'공부기록용' 카테고리의 다른 글
| [ SQLD ] 데이터 모델과 성능 240801 (0) | 2024.08.01 |
|---|---|
| [ SQLD ] 데이터 모델링의 이해 240729 (0) | 2024.07.29 |
| [ SQLD ] 데이터 모델링의 이해 240728 (0) | 2024.07.28 |
| [ SQLD ] 기록용 (1) | 2024.07.27 |
| [ SQLD ] 데이터 모델링 (0) | 2024.07.25 |



